
Amazon Aurora Limitless Databaseの3種類のテーブルの違い ~ Standard/Sharded/Reference ~
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWSの提供する分散データベースAmazon Aurora Limitless Databaseには3種類のテーブルタイプが存在します。
- Standard : 特定のシャードに保存されるデフォルトのテーブルタイプ
- Sharded : 複数のシャードに分散されるタイプ
- Reference : すべてのシャードにレプリケートされるタイプ
複数の Sharded テーブルを同じシャードキーで管理すると、 Collocatedタイプとなります。これらの違いを確認します。
サンプルスキーマ
検証のために、ECサイトを想定したAWSが提供する次のLimitless Database用のスキーマを活用します。
このサンプルでは、一度Standardテーブルとして作成し、Sharded/Referenceテーブル化します
READMEに従って、以下の順で DDL を適用しましょう。
create_standard_tables_ec_sample_schema.sqlconvert_standard_tables_to_limitless_ec_sample_schema.sql
Limitless Database とシャーディング
Limitless Databaseはシャーディングによる水平分割により、同時処理と高い書き込みスループットを実現しています。
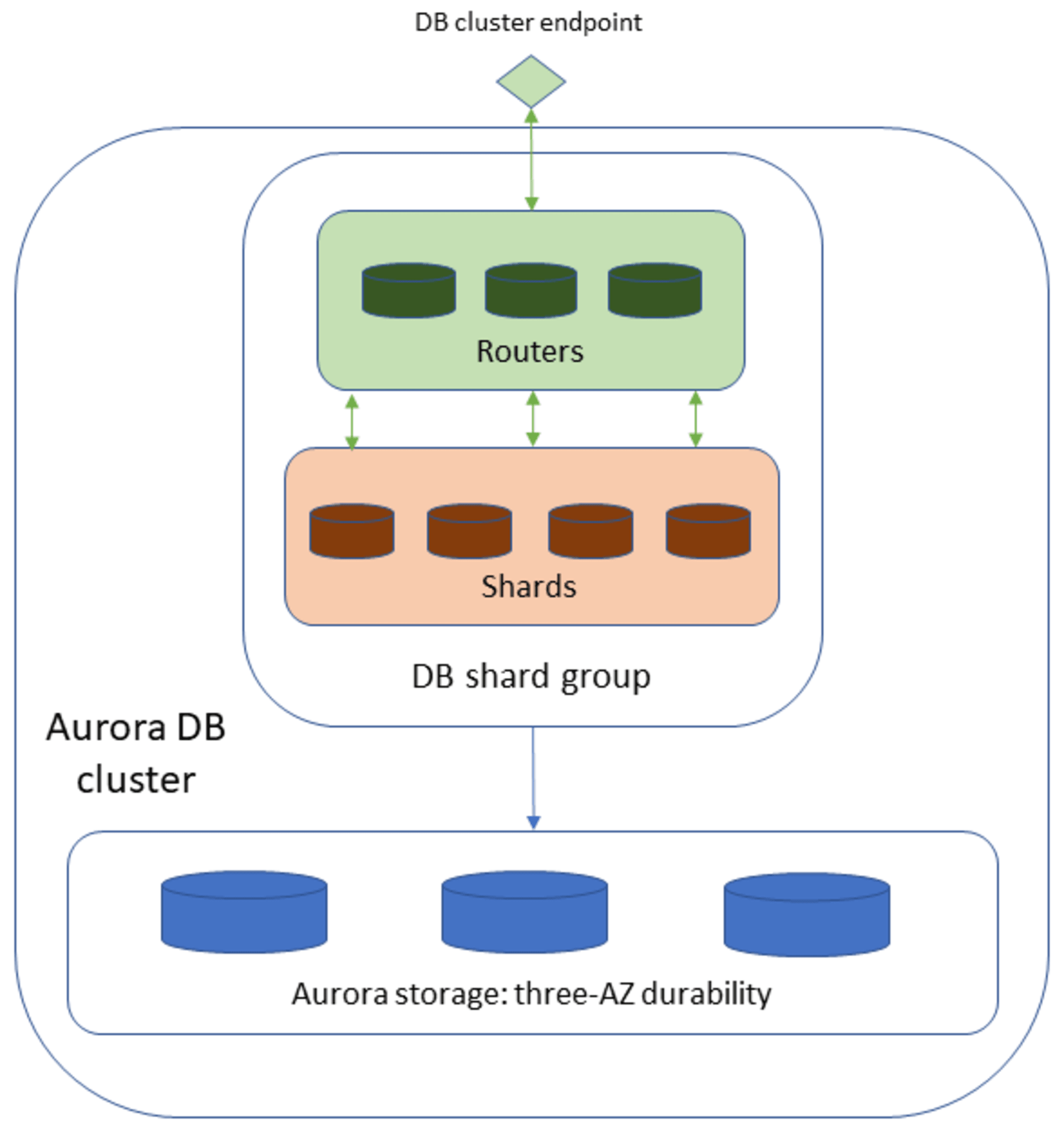
※ 引用元
3種類のテーブルとシャードへのデータ格納方法の違い
シャードへのデータ格納方式として、以下の3種類のテーブルを選択できます。
- Standard : 特定のシャードに保存されるデフォルトのテーブルタイプ
- Sharded : 複数のシャードに分散されるタイプ
- Reference : すべてのシャードにレプリケートされるタイプ
特に、以下のような特性を持ったデータは Sharded テーブル に最適です
- データの一部だけで処理できる
- テーブルサイズが非常に大きい
- 他のテーブルよりデータの伸びが大きい
ECサイトを例にシャーディング戦略を考える
サンプルスキーマのECサイトでは、以下のデータを扱います
- 顧客データ
- 注文データ
- 製品データ
次のようなER図になります
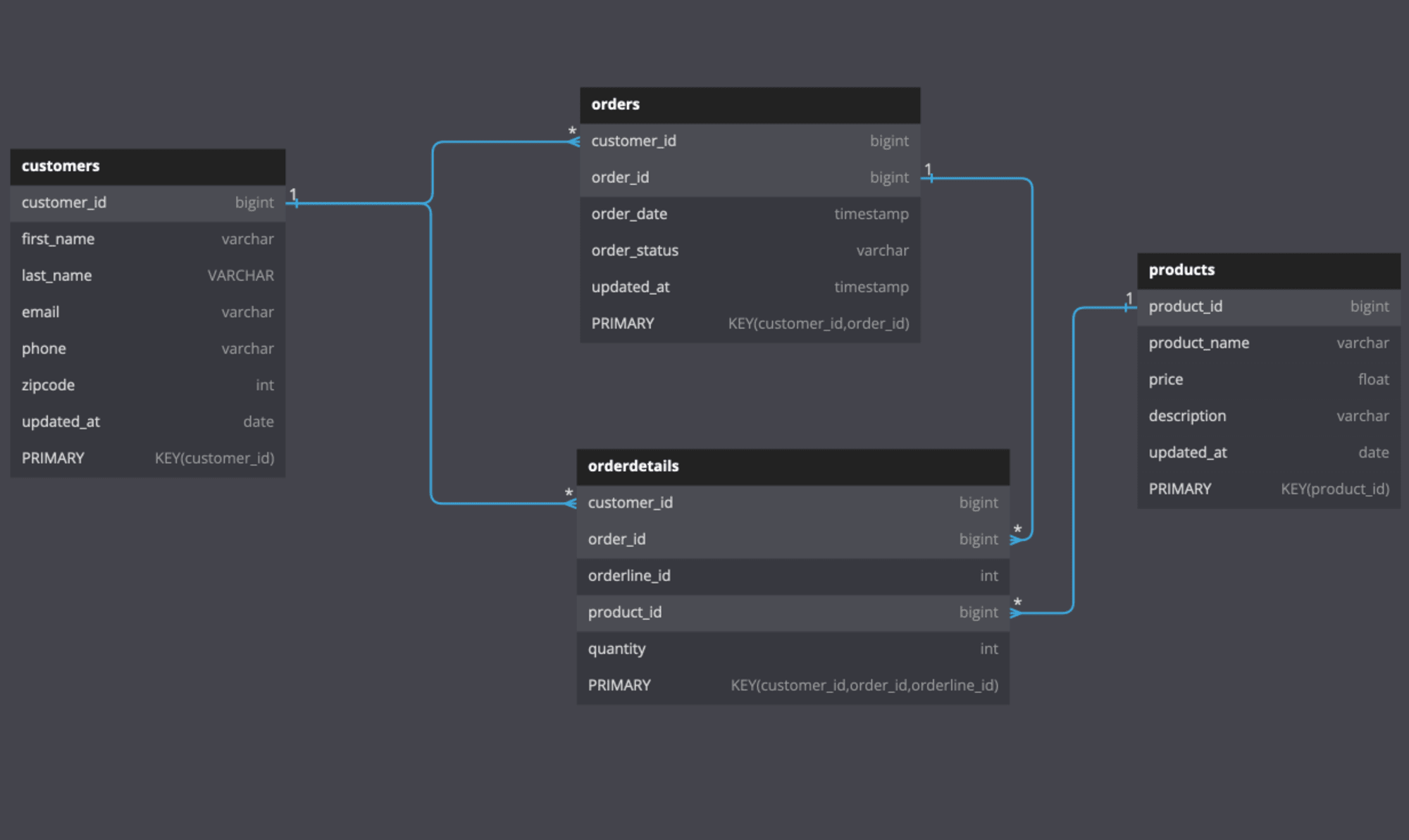
※ 引用元
素のPostgreSQL向けに書き直したDDL
-- customers テーブル
CREATE TABLE ec_sample.customers (
customer_id BIGINT PRIMARY KEY,
first_name VARCHAR NOT NULL,
last_name VARCHAR NOT NULL,
email VARCHAR NOT NULL,
phone VARCHAR NOT NULL,
zipcode INT,
updated_at DATE
);
-- orders テーブル
CREATE TABLE ec_sample.orders (
customer_id BIGINT,
order_id BIGINT,
order_date TIMESTAMP,
order_status VARCHAR,
updated_at TIMESTAMP,
PRIMARY KEY (customer_id, order_id),
FOREIGN KEY (customer_id) REFERENCES ec_sample.customers(customer_id)
);
-- orderdetails テーブル
CREATE TABLE ec_sample.orderdetails (
customer_id BIGINT,
order_id BIGINT,
orderline_id INT,
product_id BIGINT,
quantity INT,
PRIMARY KEY (customer_id, order_id, orderline_id),
FOREIGN KEY (customer_id, order_id) REFERENCES ec_sample.orders(customer_id, order_id),
FOREIGN KEY (product_id) REFERENCES ec_sample.products(product_id)
);
-- products テーブル
CREATE TABLE ec_sample.products (
product_id BIGINT PRIMARY KEY,
product_name VARCHAR,
price FLOAT,
description VARCHAR,
updated_at DATE
);
Limitless Database化したテーブル設計
このスキーマをLimitless Database向けにテーブル設計したのが、次の図です
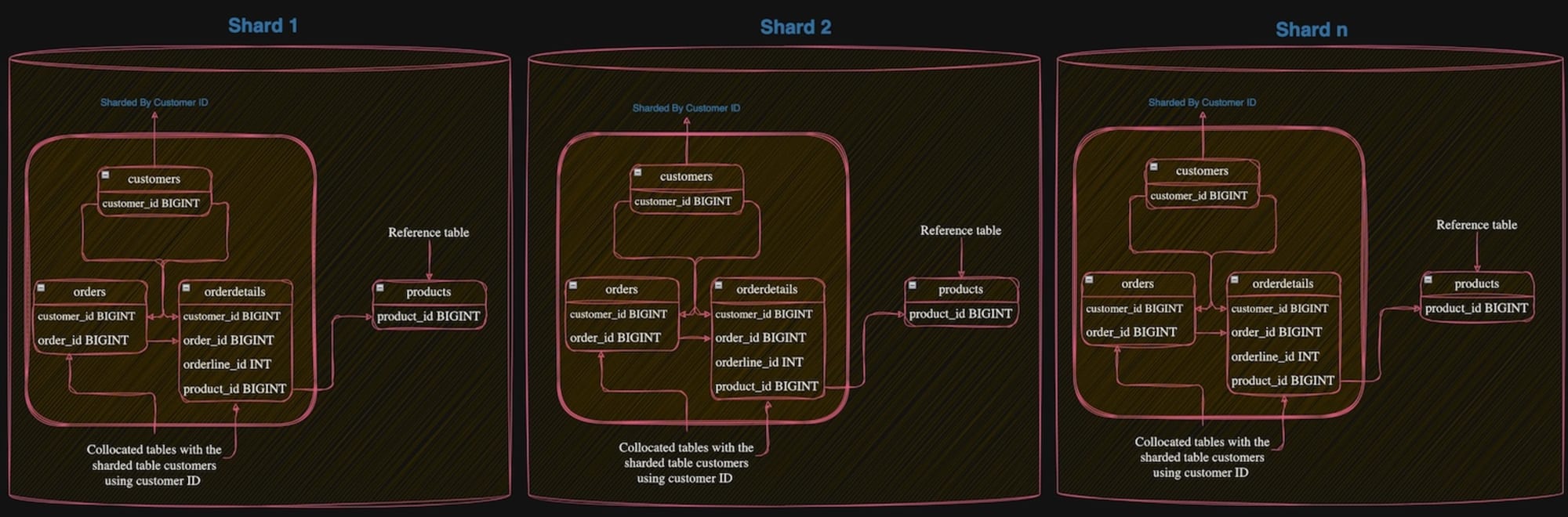
※ 引用元
製品データ(productsテーブル)は Referenceテーブル として全データを各シャードに配置します。
顧客データ(customersテーブル)と注文データ(ordersとorderdetailsテーブル)は顧客ID(customer_id)をシャードキーとした Shardedテーブル として シャーディングします。
このようにすることで、顧客IDをキーにデータ操作する場合、データアクセスがシャード内に閉じ、うまくスケールします。
特に
- 顧客データ(customersテーブル)
- 注文データ(ordersテーブル)
- 注文詳細データ(orderdetailsテーブル)
のように、複数のテーブルを同じシャードキーでシャーディングしたテーブルを Collocatedテーブル といいます。テーブル JOIN 時もシャードをまたがないクエリとなるため、パフォーマンスの向上が期待できます。
テーブルタイプの指定
テーブルタイプを明示しない場合、Standardタイプで作成されます。
テーブルタイプの指定方法は、以下の2種類があります
- セッション変数でタイプを指定
- スタンダードテーブルから変換
セッション変数でタイプを指定
rds_aurora.limitless_create_table_mode でテーブルタイプ(Sharded/Reference) を指定します。
Sharded テーブルの例
BEGIN;
SET LOCAL rds_aurora.limitless_create_table_mode='sharded';
SET LOCAL rds_aurora.limitless_create_table_shard_key='{"id"}';
CREATE TABLE items(id int, val int, item text);
COMMIT;
Reference テーブルの例
BEGIN;
SET LOCAL rds_aurora.limitless_create_table_mode='reference';
CREATE TABLE colors(color_id int primary key, color varchar);
COMMIT;
テーブルモードをデフォルトの Standard に戻すには、次のステートメントを実行します。
RESET rds_aurora.limitless_create_table_mode;
プロシージャでスタンダードテーブルから変換
Standardテーブルをプロシージャで Sharded、及び、Reference テーブルに変換できます。このプロシージャは同期実行される点にご注意ください
Sharded テーブル化
rds_aurora.limitless_alter_table_type_sharded プロシージャを利用すると、Standard テーブルを Sharded テーブルに変換できます。
postgres_limitless=> CREATE TABLE customer (customer_id INT PRIMARY KEY NOT NULL, zipcode INT, email VARCHAR);
CREATE TABLE
postgres_limitless=> \d
List of relations
Schema | Name | Type | Owner
--------+----------+---------------+----------
public | customer | foreign table | postgres
(1 row)
postgres_limitless=> CALL rds_aurora.limitless_alter_table_type_sharded('public.customer', ARRAY['customer_id']);
CALL
postgres_limitless=> \d
List of relations
Schema | Name | Type | Owner
--------+------------------+-------------------+-----------------------------------
public | customer | partitioned table | postgres
public | customer_fs00001 | foreign table | rds_aurora_limitless_tables_owner
public | customer_fs00002 | foreign table | rds_aurora_limitless_tables_owner
(3 rows)
postgres_limitless=> \d customer
Partitioned table "public.customer"
Column | Type | Collation | Nullable | Default
-------------+-------------------+-----------+----------+---------
customer_id | integer | | not null |
zipcode | integer | | |
email | character varying | | |
Partition key: HASH (customer_id)
Number of partitions: 2 (Use \d+ to list them.)
Typeがpartitioned table となり、 テーブル名_fsNN という連番の foreign table が作成されました。
CALL rds_aurora.limitless_alter_table_type_sharded('スキーマ名.変換するテーブル名', ARRAY['シャードカラム'], 'スキーマ名.collocateするテーブル名'); のように最後の引数で collocate するテーブルを指定すると、 Collocatedテーブル に変換できます。
Reference テーブル化
rds_aurora.limitless_alter_table_type_reference プロシージャを利用すると、standard テーブルを reference テーブルに変換できます。 全データを各シャードに配置する reference テーブルなので、引数にシャードキーはありません。
postgres_limitless=> CREATE TABLE zipcodes (zipcode INT PRIMARY KEY, details VARCHAR);
CREATE TABLE
postgres_limitless=> CALL rds_aurora.limitless_alter_table_type_reference('public.zipcodes');
CALL
postgres_limitless=> \d
List of relations
Schema | Name | Type | Owner
--------+----------+---------------+----------
public | zipcodes | foreign table | postgres
(1 row)
postgres_limitless=> \d zipcodes
Foreign table "public.zipcodes"
Column | Type | Collation | Nullable | Default | FDW options
---------+-------------------+-----------+----------+---------+-------------
zipcode | integer | | | |
details | character varying | | | |
Server: _rds_aurora_internal_shard_4_0
FDW options: (schema_name 'public', table_name 'zipcodes', aurora_table_type 'reference', aurora_replication_tag 'replicationTag')
テーブルタイプの確認
テーブルタイプは rds_aurora.limitless_tables ビューの table_type カラムから確認できます。
postgres_limitless=> SELECT * FROM rds_aurora.limitless_tables;
table_gid | local_oid | schema_name | table_name | table_status | table_type | distribution_key
-----------+-----------+-------------+--------------+--------------+------------+--------------------
16004 | 17779 | ec_sample | customers | active | sharded | HASH (customer_id)
16006 | 17803 | ec_sample | orderdetails | active | sharded | HASH (customer_id)
16005 | 17791 | ec_sample | orders | active | sharded | HASH (customer_id)
16007 | 17809 | ec_sample | products | active | reference |
16009 | 17825 | ec_sample | std_tbl | active | standard |
(5 rows)
Collocatedテーブルは rds_aurora.limitless_table_collocation ビューから確認できます。同じcollocation_idを持つテーブルは、同じシャードに分散配置されます。
postgres_limitless=> SELECT * FROM rds_aurora.limitless_table_collocations ORDER BY collocation_id;
collocation_id | schema_name | table_name
----------------+-------------+--------------
16002 | ec_sample | customers
16002 | ec_sample | orders
16002 | ec_sample | orderdetails
(3 rows)
rds_aurora.limitless_table_collocation_distributions ビューから collocation のキー分布を確認できます
postgres_limitless=> SELECT * FROM rds_aurora.limitless_table_collocation_distributions ORDER BY collocation_id, lower_bound;
collocation_id | subcluster_id | lower_bound | upper_bound
----------------+---------------+----------------------+---------------------
16002 | 5 | -9223372036854775808 | 0
16002 | 4 | 0 | 9223372036854775807
(2 rows)
クエリの実行計画からシャードアクセスの違いを確認
- Standard : 特定のシャードに保存されるデフォルトのテーブルタイプ
- Sharded : 複数のシャードに分散されるタイプ
- Reference : すべてのシャードにレプリケートされるタイプ
というシャーディングの違いをクエリの実行計画から確認します。
3種類のテーブル単体に SELECT クエリを投げて実行計画を確認します
-- standard table
EXPLAIN SELECT 1 FROM ec_sample.std_tbl;
QUERY PLAN
------------------------------------------------------
Foreign Scan (cost=100.00..101.00 rows=100 width=0)
Single Shard Optimized
(2 rows)
-- reference table
EXPLAIN SELECT 1 FROM ec_sample.products;
QUERY PLAN
------------------------------------------------------
Foreign Scan (cost=100.00..101.00 rows=100 width=0)
Single Shard Optimized
(2 rows)
Standed と Reference テーブルはシャードを横断せずに 特定シャードへのアクセスですべてのデータにアクセスできる single-shard query のため、Single Shard Optimized という文字を確認できます。
ドキュメントから引用します
A single-shard query is a query that can be run directly on a shard while maintaining SQL ACID semantics. When such a query is encountered by the query planner on the router, the planner detects it and proceeds to push down the entire SQL query to the corresponding shard.
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/limitless-query.single-shard.html
一方で、シャーディングされた customer テーブルはシャードをまたぐ 分散クエリ(distributed query)となるため、実行計画にこの文字が見当たりません。
-- sharded table
EXPLAIN SELECT 1 FROM ec_sample.customers;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Append (cost=100.00..3121.05 rows=6826 width=4)
-> Async Foreign Scan on customers_fs00001 customers_1 (cost=100.00..1543.46 rows=3413 width=4)
-> Async Foreign Scan on customers_fs00002 customers_2 (cost=100.00..1543.46 rows=3413 width=4)
(3 rows)
ドキュメントから引用します
Distributed queries run on a router and more than one shard. The query is received by one of the routers. The router creates and manages the distributed transaction, which is sent to the participating shards. The shards create a local transaction with the context provided by the router, and the query is run.
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/limitless-query.distributed.html
テーブル単体へのクエリであれば single sharded だった Reference テーブルへのクエリも、Sharded テーブルと JOIN すると、分散クエリになります。
EXPLAIN (VERBOSE, COSTS OFF) SELECT 1
FROM
ec_sample.orderdetails AS od
JOIN
ec_sample.products AS p
ON od.product_id = p.product_id;
QUERY PLAN
-------------------------------------------------------------------------------
Merge Join
Output: 1
Merge Cond: (p.product_id = od.product_id)
-> Sort
Output: p.product_id
Sort Key: p.product_id
-> Foreign Scan on ec_sample.products p
Output: p.product_id
Remote SQL: SELECT product_id FROM ec_sample.products
-> Sort
Output: od.product_id
Sort Key: od.product_id
-> Append
-> Async Foreign Scan on ec_sample.orderdetails_fs00001 od_1
Output: od_1.product_id
Remote SQL: SELECT product_id FROM ec_sample.orderdetails
-> Async Foreign Scan on ec_sample.orderdetails_fs00002 od_2
Output: od_2.product_id
Remote SQL: SELECT product_id FROM ec_sample.orderdetails
Query Identifier: -8626680185855657796
(20 rows)
最後に、ECサンプルスキーマをJOINしたSELECT クエリの VERBOSE な実行計画を参考情報として共有します。
EXPLAIN (VERBOSE, COSTS OFF) SELECT
c.customer_id,
o.*,
od.*,
p.*
FROM
ec_sample.customers AS c
JOIN
ec_sample.orders AS o
ON c.customer_id = o.customer_id
JOIN
ec_sample.orderdetails AS od
ON o.customer_id = od.customer_id AND o.order_id = od.order_id
JOIN
ec_sample.products AS p
ON od.product_id = p.product_id;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Hash Join
Output: c.customer_id, o.customer_id, o.order_id, o.order_date, o.order_status, o.updated_at, od.customer_id, od.order_id, od.orderline_id, od.product_id, od.quantity, p.product_id, p.product_name, p.price, p.description, p.updated_at
Hash Cond: (od.product_id = p.product_id)
-> Append
-> Async Foreign Scan
Output: c_1.customer_id, o_1.customer_id, o_1.order_id, o_1.order_date, o_1.order_status, o_1.updated_at, od_1.customer_id, od_1.order_id, od_1.orderline_id, od_1.product_id, od_1.quantity
Relations: ((ec_sample.customers_fs00001 c_1) INNER JOIN (ec_sample.orders_fs00001 o_1)) INNER JOIN (ec_sample.orderdetails_fs00001 od_1)
Remote SQL: SELECT r8.customer_id, r10.customer_id, r10.order_id, r10.order_date, r10.order_status, r10.updated_at, r12.customer_id, r12.order_id, r12.orderline_id, r12.product_id, r12.quantity FROM ((ec_sample.customers r8 INNER JOIN ec_sample.orders r10 ON (((r8.customer_id = r10.customer_id)))) INNER JOIN ec_sample.orderdetails r12 ON (((r8.customer_id = r12.customer_id)) AND ((r12.order_id = r10.order_id))))
-> Async Foreign Scan
Output: c_2.customer_id, o_2.customer_id, o_2.order_id, o_2.order_date, o_2.order_status, o_2.updated_at, od_2.customer_id, od_2.order_id, od_2.orderline_id, od_2.product_id, od_2.quantity
Relations: ((ec_sample.customers_fs00002 c_2) INNER JOIN (ec_sample.orders_fs00002 o_2)) INNER JOIN (ec_sample.orderdetails_fs00002 od_2)
Remote SQL: SELECT r9.customer_id, r11.customer_id, r11.order_id, r11.order_date, r11.order_status, r11.updated_at, r13.customer_id, r13.order_id, r13.orderline_id, r13.product_id, r13.quantity FROM ((ec_sample.customers r9 INNER JOIN ec_sample.orders r11 ON (((r9.customer_id = r11.customer_id)))) INNER JOIN ec_sample.orderdetails r13 ON (((r9.customer_id = r13.customer_id)) AND ((r13.order_id = r11.order_id))))
-> Hash
Output: p.product_id, p.product_name, p.price, p.description, p.updated_at
-> Foreign Scan on ec_sample.products p
Output: p.product_id, p.product_name, p.price, p.description, p.updated_at
Remote SQL: SELECT product_id, product_name, price, description, updated_at FROM ec_sample.products
Query Identifier: -3730172280485873671
(18 rows)
まとめ
Amazon Aurora Limitless Databaseを正しく活用するには、データのアクセスパターンを十分に検討した上で、テーブルの種類(Standard/Sharded/Reference)とシャードキーを設計する必要があります。
まずはリスクを許容できるシステムで試験的に導入して、肌感覚を掴みましょう。








